
An indispensable Part of Acceleration – GPU Computing
GPU Computing refers to the utilization of Graphics Processing Units (GPU) in order to speed up the computation of tasks in computing systems. GPUs have been evolving over time and now they have become indispensable for several application areas. In this article, we will give a brief overview of GPU Computing.
GPUs are a class of hardware accelerators. Readers of this article may have heard of other accelerators such as ASICs (Application Specific Integrated Circuits), DSPs (Digital Signal Processors) and FPGAs (Field Programmable Gate Arrays) previously. ASICs are integrated circuits designed specifically for an application. Designers use hardware description languages (e.g., Verilog, VHDL) or already designed IP (Intellectual Property) blocks to design the dedicated circuit. Designs make use of the standard cells that are optimized either for speed, power or area and fabricated in plants using semiconductors. Since they cannot be modified after fabrication and require millions of dollars of non-recurring engineering costs, they require a very long and careful process to design and produce. FPGAs, originally invented by Xilinx, provide flexibility over ASICs with providing reconfigurable logic to the hardware designers. Designers again describe their intended hardware in VHDL or Verilog and their design is mapped to the reconfigurable blocks on the FPGA. Thus, FPGAs give chance to redesign the hardware flexibly. DSPs, on the other hand, are CPU-like processing units that have extensions for several mathematical operations used for signal processing purposes.
Evolution of GPUs and GPU Computing
When it comes to GPUs, they firstly emerged in1980s as hardware implementations supporting the display of 2D (2 dimensional) graphics primitives [1]. During those times, there was a trend of enriching software techniques via hardware accelerators. In 1990s GPUs started to be used for the acceleration of 3D graphics. Gaming consoles like PlayStation and Nintendo incorporated GPU accelerated graphics cards. GPUs were implementing the OpenGL and Microsoft DirectX APIs (Application Programming Interface) in their fixed-function pipelined hardware. Over time, fixed-function pipelines were started to insufficient for the 3D processing needs of gaming and media productions. To meet the demands, the fixed-function pipeline of GPUs were enriched with configurable pipeline stages. Thus, users could provide codes (aka shaders) to control the operation of those stages. OpenGL and DirectX APIs started to support shaders.
API and architecture support for shaders, initially for pixel shaders, extended to include vertex, geometry, and other shaders. Over time all these shaders were combined under the umbrella of Unified Shader Model. By means of this model, separate shader programming units in the pipelines were evolved into a single type of shader core that can perform all of the shader operations. Hence, the workload could be assigned dynamically to the different unified shader cores. Thus shaders became programmable. GPU makers adopted the unified shader model in their architectures.
Initially, graphics APIs were the only way for programmers to program GPUs. As we explained previously, graphics programmers were able to write shader codes for graphics processing needs. However, programmers from other fields were not able to use it since they were not familiar with converting their problems into graphics problems. For GPUs to be used of general purpose programming, a higher level language that provides a programmer-friendly environment and that deals with conversion operations were needed. Stream-based languages (e.g., Brooks, Scout, Glift) were born with this reason, which gave chance to programmers to use GPUs for general purpose programming. Thus, GPGPU – General Purpose GPU computing was started which considered GPUs as a possible replacement of CPUs.
After the birth of the GPGPU, the trend was offloading all of the computation tasks to GPUs. However, it was realized that using GPUs for every computation job was not efficient. Since GPUs are connected to the host system via a bus, transfer of data to and from the GPU is needed as shown in the Fig. 1 below. For some cases, computation cost on the host CPU may be lower than the transfer cost over the bus plus the computation cost at the GPU device. In addition to this, GPUs are mostly suitable for problems that can be solved with high parallelism. If a big portion of a problem consists of parts that cannot be parallelized, then it would use the GPU resources inefficiently.
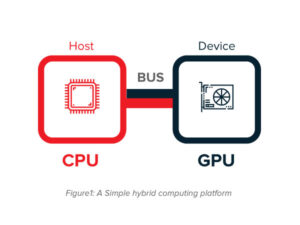
GPGPU computing eventually turned into GPU computing which aimed to create a hybrid computing platform with CPUs and GPUs. In GPU computing, programs to run on the hybrid platform consists of parts that use GPUs for accelerated computing and the rest of the code is run on the host CPU. Since GPUs started to be used for the programming needs of general purpose programmers, GPU makers incorporated general purpose programming capabilities to their architectures in the form of hierarchical memory, DMA-transfers, double precision, etc.
Building Blocks of GPUs
Although Fig. 1 shows the most common case where GPU is discretely connected to the host through a bus (e.g., PCI Express), GPUs can be integrated to the host as well [2]. In the earlier case, GPU makes use of its own memory and has a DMA engine for data transfers with the host, whereas in the latter case, it shares the same memory with CPU and does not need a DMA.
Building blocks of a sample GPU architecture (i.e., Nvidia GF100) is shown in Fig.2. As shown in the figure, GPUs have execution engines which are made of hundreds of GPU cores. These engines are called Streaming Multiprocessors (SM) in Nvidia and Compute Units (CU) in AMD respectively. In GPU programming, tasks that are offloaded to the GPUs for parallel processing are called as “kernels”. Such tasks usually have blocks that run on SMs or CUs and each block can have tens of threads [3]. Scheduling of these blocks to the corresponding SM or CU is performed by the GPU scheduler whose implementation is kept hidden from the programmers. In each SM or CU, threads within the kernel block are scheduled in groups of threads named as “warp” in Nvidia and “wavefront” in AMD [3,4]. Threads in the same warp/wavefront are executed at the same time in parallel within the SM/CU. Both Nvidia and AMD schedulers assign multiple warps/wavefronts to SMs/CUs for a common purpose: hiding the data transfer latency. When a group of thread is waiting to access data, during that time ready group of threads can run on the SMs/CUs, hence latency is hidden.

Figure 2: Building blocks of a sample GPU architecture[7].
GPUs can be programmed for general purpose applications using the APIs like CUDA for Nvidia GPUs and OpenCL for both AMD and Nvidia GPUs.
A typical GPU program flow consists of the following steps:
- Load source code containing the kernel
- Create the context to interact with the GPU
- Create a command queue within the context
- Create memory buffers in device memory to send data to the device
- Write corresponding data to the created buffers on the device
- Create kernel program from the loaded source code in the created context
- Build the kernel program
- Create the kernel from the program
- Set kernel arguments using the created buffer information
- Execute the kernel
- Read the results back to the host
- Release the resources.
How are GPUs utilized for computing?
There are several ways that GPUs can be utilized for computing purposes for compute-intensive tasks that can be parallelized.
We can program GPUs using APIs like CUDA and OpenCL. CUDA (Compute Unified Device Architecture) is Nvidia’s API which is based on the C programming language [1]. OpenCL (Open Computing Language) is a standardized API along with C-like language that is used to program compute devices in heterogeneous platforms including GPUs [5].
GPUs can be used for data-parallel applications as we can run Single Instruction Multiple Data (SIMD) model on GPUs. Each SP/CU can run the same computation on a piece of data in this model of working. Programming languages like C++ have support for applying the data parallelism.
GPUs can also be used with task parallelism. In this form of execution, computation tasks are usually divided into sub-tasks that form a Directed Acyclic Graph (DAG) with dependencies. These sub-tasks can be run on GPU SPs/CUs.
Several GPUs can be connected to a host and host applications can make use of them. However, a host can also make use of GPUs that are not directly connected to it via a bus. Message passing interfaces like MPI can be used by host applications to use GPUs that are not attached to host but can be reached via a network connection. Thus, GPUs can be integrated into the high performance computing cluster environments.
GPUs can also be utilized by means of libraries with GPU acceleration support. If GPU support is enabled, then the corresponding libraries can use GPUs in the platform to speed up the computation tasks. For example, ImageMagick [8] and FFMPEG [9] libraries have GPU support.
Application Areas of GPU Computing
GPUs are used not only for graphics processing or scientific computing but also used for computing tasks in various industries. They are actively being used in industries of finance, environment, data science, security and defense, fluid dynamics, electronic design automation, industrial inspection, media and entertainment, medical imaging, oil and gas, computational chemistry and biology (bioinformatics, microscopy, molecular dynamics, quantum chemistry), numerical analytics, scientific visualization, safety and security [6].
Studies show that GPUs will be playing a crucial role in automotive tasks for assisted and self-driving technologies [2]. For this aim, GPUs have been used in environment perception, vehicle detection, lane detection, pedestrian detection, traffic sign recognition, eye closure detection, speech recognition, route planning, etc.
GPUs can also play a significant role for edge computing applications which aim to bring computing capabilities of the cloud to the edges of the networks. Container technologies like Docker have been very popular during recent years for Cloud and Edge Computing platforms. GPU manufacturers started to provide GPU-enabled containers with this reason.
In Medianova, we use GPUs for fast image transformations and video processing for our high-performance CDN services.
Conclusion
GPU computing has been evolving over the years and now it is an indispensable part of computing systems in various application areas. As with the other technologies, it has emerged from the needs. We believe that GPUs will play a crucial role in the development of the smart applications of the future.

References
- Augonnet, C. (2011). Scheduling Tasks over Multicore machines enhanced with accelerators: a Runtime System’s Perspective (Doctoral dissertation). Retrieved from https://tel.archives-ouvertes.fr/tel-00777154/document
- Xu, Y., Wang, R., Li, T., Song, M., Gao, L., Luan, Z. and Qian, D. (2016). Scheduling tasks with mixed timing constraints in GPU-powered real-time systems. Proceedings of the 2016 International Conference on Supercomputing. Istanbul, Turkey.
- Cruz, R., Drummond, L., Clua, E. and Bentes, C. (2017). Analyzing and estimating the performance of concurrent kernels execution on GPUs. WSCAD 2017 – XVIII Simposio em Sistemeas Computacionais de Alto Desempenho.
- Graphics Core Next. (n.d.). In Wikipedia. Retrieved April 22, 2019, from https://en.wikipedia.org/wiki/Graphics_Core_Next
- (n.d.). In Wikipedia. Retrieved April 24, 2019, from https://en.wikipedia.org/wiki/OpenCL
- GPU-Accelerated Applications. (2019). Retrived April 24, 2019, from https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/gpu-applications-catalog.pdf
- Nvidia GF100. (2010).[White Paper]. Retrieved April 24, 2019, from https://www.nvidia.com/object/IO_89569.html.
- (2019). Retrieved April 24, 2019, from https://imagemagick.org/index.php.
- (2019). Retrieved April 24, 2019, from https://ffmpeg.org/.
