
What Is GraphQL And How To Make It Faster Using a CDN
This Is How You Can Make GraphQL Faster Using a CDN
REST has been the dominant standard in designing web APIs for the past decade. Though REST offers many great ideas and tools such as stateless servers or structured access to resources, it has shown that it is inflexible and sometimes insufficient to meet the new requirements of the changing clients. GraphQL which was firstly developed by Facebook internally and then have been opened to the public in 2015, is presented as a revolutionary new way to think about APIs.
GraphQL, as its name suggests, is a query language for your APIs. It lets you send queries to get exactly what you are looking for in one request, instead of the traditional way of dealing with rigid server-defined endpoints. As we mentioned earlier GraphQL was initially developed by Facebook to cope with the limitations they had with traditional REST APIs.
What is the problem with REST API?
In order to clarify the problem with REST API, I’d like to give you an example from Facebook. Imagine you want to display a list of posts by a specific user and under each post, you want to show the list of likes and in this list, you want to have names and profile pictures of the users. In order to achieve this, you got to tweak your posts API and let it include an array of likes containing user objects. It’s gonna be something like this:

REST API might work well till here but let’s make it a bit more complicated and think of doing this operation on a mobile app. In this scenario loading all those extra data will slow down your mobile app, so the solution would be to add two endpoints, one with likes and one without them.
Let’s not stop here and make it even more complicated. let’s think that posts are stored in a MySQL database, while likes are in a Redis store.
As you can imagine Facebook has to deal and manage many API clients and data sources and here’s where powerful REST APIs start to show their weakness.
GraphQL is the solution
If you are curious about how Facebook dealt with the problem we explained earlier, in one sentence we can say: GraphQL was the solution they came up with. They altered multiple dumb endpoints with a single smart endpoint that can accept complex queries and respond with data in the shape the client queries.
GraphQL layer in fact lies in between the client and the data sources. It receives clients’ requests and then fetches the necessary data according to the instructions given. In order to clarify how GraphQL works let’s consider another example from Facebook again. Let’s say we want to extract the titles of the posts of a specific user. Also, we are interested to get the last 3 followers of that user from the same screen. Below are the procedures you need to follow in REST API and GraphQL to get what you need.
1- REST API Scenario:
If you wish to get this data using REST API you got to access multiple endpoints such as /users/ endpoint where you will fetch initial user data. Moreover, you probably will have to request another endpoint such as /users//posts to return all of the posts of that specific user, or any user. Finally, there should be another endpoint like /users//followers which returns the list of followers of the user.
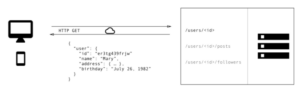
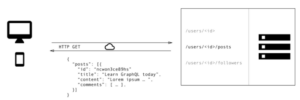
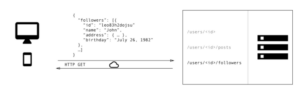
As you can see here with REST API you need to make three different requests to different endpoints to fetch the data you need. Also, you get excessive data from these endpoints which you don’t need such as address or birthday.
2- GraphQL scenario:
But if you want to fetch this data using GraphQL you will only need to send a single query to GraphQL server. The server will answer with a JSON object fulfilling your requirements.
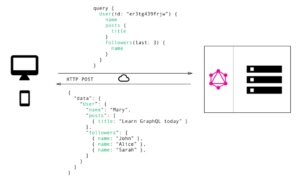
As you can see in the GraphQL request, you only specify what you need in the query, and as you can see in the server’s response the response has the exact structure as the request you sent.
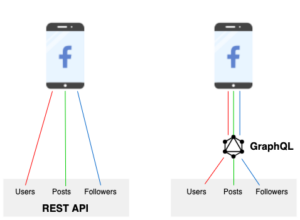
The graphic below shows a comparison of REST API vs GraphQL.
How to make your API faster?
As you may know, with the emerge of modern coding architectures, web and mobile applications use APIs such as REST API or GraphQL. Many of the requests made to a GraphQL endpoint are POST or GET requests. These requests are responded with a JSON object. In a modern web application, all the clients are API consumers and they get the result shown to them by making different API requests. These different API requests sent by consumers or clients will create a large number of requests flow into your API endpoint. In the case of a popular web/mobile application, these requests can reach millions of API calls each day. But the questions here are that:
- Do we need to make an API call for every visitor?
- How often does this information need to be updated?
- Will updating this API response every 10 minutes, for example, still work well?
Yes, you are right! Sometimes you don’t need to make an API call for every visitor and you can use the same API’s response. By caching this kind of requests you can reduce the number of API calls to your database or backend. With API response caching you can reduce API requests’ latency and consequently improve your performance. You can use Medianova’s API Caching platform to cache such responses and benefit from the advantages of this feature.
In the following section, we will explain the benefits using Medianova API Caching will bring for you.
What Benefits API Response Caching will have for you?
Probably one of the most important performance metrics that many applications aim to reduce is latency. Caching GraphQL GET requests is quite easy and straightforward. Caching POST requests might seem tricky at first glance but by adding Expire header of Cache-Control header with a directive we can cache some of the POST requests as well. Caching these API calls in the edge nodes of Medianova will cause these frequent calls to be served from Medianova’s distributed cluster of nodes, in locations closer to the clients. This, as a result, will reduce the latency.
So let’s see how will it affect your latency. if you check the picture below, it shows two cases one without API Response Caching (1) and one with Medianova API Caching (2,3). You can see for this specific GraphQL API if you don’t use API response caching, your response time is something around 500ms (560ms to be specific in number 1) But after deploying Medianova API Caching and in case of a HIT situation the response time will decrease magnificently to 23ms in 3.
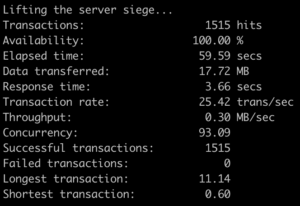
In order to show the exact performance effect using API caching will have, we ran another test using Siege with 100 concurrent users for 1 minute for a GraphQL API with and without API caching separately. All other elements of both test cases, such as environment and objects were identical. Here’s the result.
Test result without API Response Caching:
Test result with API Response Caching:
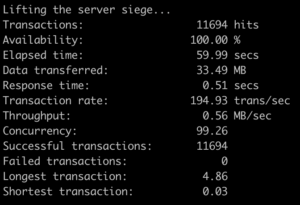
In this test, by using Medianova API caching, we could increase the Transaction Rate from 25.42 Transaction per second to 194.93 transactions per second. This means by using API Response Caching you can do 169.51 more transactions in a second.
Wow, this is a 666.83% improvement in performance!
There are other benefits for API Caching such as Security, Availability, and Scalability which are out of the scope of this article.
At Medianova, we follow cutting edge technologies and products to keep up with the market trends and the fast-growing requirements of our customers.


