
GPU ile Hesaplama: Hızlanmanın Vazgeçilmez Parçası
GPU ile hesaplama bilgisayar sistemlerinde Grafik Hesaplama Birimleri’nin (Graphics Processing Units – GPU) hesaplama işlerini hızlandırmak amacıyla kullanılması anlamına gelmektedir. GPU’lar zaman içinde evrime uğramışlar ve günümüzde birçok uygulama alanı için hesaplama işlemlerinin vazgeçilmez bir parçası haline gelmişlerdir. Bu yazımızda sizlere GPU ile hesaplama konusunda özet niteliğinde genel bilgi vermeye çalışacağız.
GPU’lar hızlandırıcı donanımlarının bir sınıfını oluşturmaktadır. Okuyucular daha önce diğer hızlandırıcıları, Uygulamaya Özgü Tümdevre (Application Specific Integrated Circuit – ASIC), Sayısal İşaret İşleyiciler (Digital Signal Processors – DSPs) ve Sahada Programlanabilir Kapı Dizileri (Field Programmable Gate Arrays – FPGAs), duymuş olabilirler. ASIC’ler uygulamalara özel olarak tasarlanan tümdevrelerdir. Tasarımcılar donanım tasarlama dillerini (örn. Verilog, VHDL) ya da daha önce tasarlanmış olan özel blokları (Intellectual Property – IP) kullanarak uygulamalarına özgü devreyi tasarlarlar. Ortaya çıkan tasarım da güç tüketimi, alan ya da hız konusunda optimize edilmiş standart hücrelerle yarı iletkenler kullanılarak üretilir. Üretim sonrasında üzerinde değişiklik yapılamadığı ve milyonlarca dolarlık mühendislik maliyeti (bir defalık maliyet – nonrecurring engineering cost) olduğu için ASIC’lerin tasarlanması ve üretilmesi dikkat ve zaman gerektiren süreçlerdir. İlk Xilinx tarafından geliştirilen FPGA’lar ise sundukları tekrardan konfigüre edilebilir mantıksal bloklarıyla ASIC’lere göre esneklik sağlarlar. Tasarımcılar ASIC’te olduğu gibi yine donanımlarını VHDL ya da Verilog’da tanımlarlar ve sonrasında tasarımları FPGA’nın bileşenleri olan tekrar konfigüre edilebilen bloklara yerleştirilir. Bu bloklar yeniden programlamaya izin verdiği için de FPGA’lar özel donanım tasarımlarıyla hızlanmayı hedefleyen uygulamalar için esnek bir çözüm oluşturmaktadırlar. DSP’ler ise CPU benzeri işlem birimleridir. Mimarilerinde normal işlemcilerde yapılara ek olarak işaret işlemede kullanılan birçok matematiksel işlemler için bileşenlere sahiptirler.
GPU’ların ve GPU ile Hesaplamanın Evrimi
GPU’lar ilk olarak 1980’lerde 2 boyutlu (2 Dimensional – 2D) grafik bileşenlerini destekleyen donanımlar olarak ortaya çıkmışlardır [1]. O sıralarda yazılımların donanımsal hızlandırıcılarla zenginleştirilmesi yönünde bir akım vardı. PlayStation ve Nintendo gibi oyun konsolları GPU hızlandırıcılarına konsollarında yer vermeye başladılar. GPU’lar sabit bir iş hattından oluşan donanımlarında OpenGL ve Microsoft DirectX Uygulama Geliştirme Arayüzleri’ni (Application Programming Interface – API) gerçekliyorlardı. Zaman içinde GPU’ların sabit iş hatları oyun ve medya uygulamalarının 3 boyutlu hesaplama işlemleri için yetersiz kalmaya başladı. İstekleri karşılayabilmek için sabit iş hatları konfigüre edilebilir iş hattı aşamalarıyla zenginleştirildi. Böylelikle kullanıcılar konfigüre edilebilir iş hattı bölümlerini kontrol edebilmek için shader adı verilen kodlar geliştirebilir hale geldiler. OpenGL ve DirectX API’leri shader programlarına destek vermeye başladı.
Shader programcıklarına programlama (API) ve mimari desteği ilk olarak piksel tipindeki shader programları içindi. Sonrasında ise vertex, geometri ve başka shader tipleri de desteklenmeye başlandı. Zaman içinde ise tüm shader tipleri Bütünleşik Shader Modeli (Unified Shader Model) şemsiyesi altına toplandı. Bütünleşik model sayesinde GPU mimarilerindeki farklı tipleri destekleyen farklı shader yapıları tek ve tüm tipleri destekleyen shader yapılarıyla yer değiştirerek evrime uğradı. Böylelikle iş yükünün dinamik bir şekilde mimaride uygun durumda olan shader yapılarına atanabilmesi ve çalıştırılabilmesi mümkün hale geldi. Shader yapıları programlanabilir bir nitelik kazandılar. GPU üreticileri dinamik olarak iş yükü atamasına izin veren ve programlamaya daha uygun olan Bütünleşik Shader Modeli’ni GPU’larında kullanmaya başladılar.
Programlama açısından baktığımızda başlangıçta programcılar için GPU programlamanın tek yolu grafik API’lerini kullanmaktı. Daha önce değindiğimiz gibi grafik programcıları grafik işleme ihtiyaçları için shader programları yazıyorlardı. Ancak diğer disiplinlerdeki programcılar problemlerini grafik işlemeyle ilişkili problemlere çeviremedikleri için GPU’ları kullanamıyorlardı. GPU’ların genel amaçlı programlama amacıyla kullanılabilmeleri için daha programcı dostu ve problemi grafik problemlerine arka planda çevirecek yüksek seviyede bir dile ihtiyaç vardı. Bu amaçla genel amaçlı programlamaya izin veren akış-temelli diller (Brooks, Scout, Glift) doğdu. Böylece Genel Amaçlı GPU ile Hesaplama (General Purpose GPU Computing – GPGPU Computing) ortaya çıkmış oldu. GPGPU hesaplama yaygınlaşmaya başladı ve CPU’larla hesaplamanın yerini GPUGPU hesaplamaya bırakacağı yönünde bir görüş belirmeye başladı.
GPGPU’nun doğuşundan sonra tüm hesaplama işlemlerinin GPU’lara aktarılması yönünde bir akım oluştu. Ancak GPU’ların tüm hesaplama görevleri için kullanılmalarının aslında o kadar da verimli bir yaklaşım olmadığı anlaşılmaya başlandı. Bunun nedenlerinden ilki GPU’ların ana yapıya (host) bir veri yoluyla bağlanmalarıdır. Bu nedenle verilerin GPU’lara taşınması ve sonrasında da sonuçların geriye taşınması gerekmektedir. GPU ve CPU’dan oluşan karma bir hesaplama ortamı basitçe Şekil 1’de gösterilmiştir. GPU’ların hesaplama problemlerinde veri yolu aracılığıyla transfer işlemleri düşünüldüğünde bazı durumlarda CPU’da hesaplama maliyeti GPU’ya transfer maliyeti ve GPU’da hesaplama maliyetinden daha uygun olabilmektedir. Bu nedenle CPU’da hesaplama daha iyi bir seçenek olmaktadır. Bunun yanında GPU’lar genel olarak yüksek seviyede paralelleştirilebilen problemler için uygundur. Eğer problemin büyük bir bölümü paralelliğe müsait olmayan parçalardan oluşuyorsa, sadece GPU kullanarak hesaplama yapmak GPU kaynaklarının verimsiz kullanılmasına neden olacaktır.
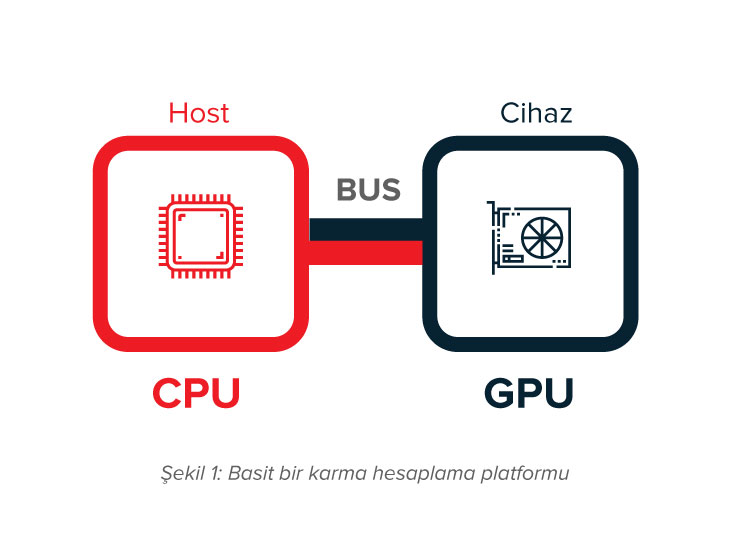
Yukarda bahsedilen nedenler itibariyle GPGPU hesaplama yerini CPU ve GPU’ların karma bir yapıda kullanıldıkları GPU ile hesaplamaya bırakmıştır. GPU ile hesaplamada karma yapıda çalışacak olan programlar GPU ile hızlandırılacak parçalar ve CPU’da çalışacak parçalardan oluşmaktadır. GPU’lar genel amaçlı programlama için kullanılmaya başlandıklarından GPU üreticileri genel amaçlı programlama için gerekli bileşenleri (hiyerarşik bellek sistemi, DMA transferleri, çift duyarlıklı sayı desteği, vb.) mimarilerinde desteklemeye başlamışlardır.
GPU’ların Bileşenleri
Şekil 1 GPU’ların ana yapıya PCI Express gibi bir veri yoluyla bağlandığı en sık rastlanan yapıyı gösterse de, aslında GPU’lar host yapısıyla bütünleşik de olabilirler [2]. Ayrık yapıda, GPU kendi belleğini kullanmakta ve host ile veri transferi DMA (Direct Memory Access) ile sağlanmaktadır. Bütünleşik yapıda ise GPU host CPU ile bir belleği ortak olarak paylaşmakta ve DMA’ya ihtiyaç duyulmamaktadır.
Örnek bir GPU’ya (Nvidia GF100) ait bileşenler Şekil 2’de verilmiştir. Şekilde gösterildiği gibi GPU’lar yüzlerce GPU çekirdeğinden oluşan hesaplama birimlerine sahiptirler. Bu hesaplama birimlerine Nvidia mimarisinde Streaming Multiprocessor (SM), AMD mimarisinde ise Compute Unit (CU) adı verilmektedir. GPU programlamada GPU’ya paralelde çalışması için gönderilen işlere “kernel” adı verilmektedir. Böyle işler SM’ler veya CU’lar üzerinde çalışacak bloklardan oluşmakta ve her blok da kendi içinde onlarca “thread” adı verilen bileşenden oluşmaktadır [3]. Blokların uygun SM ya da CU’ya atanması işini kaynak kodu/yapısı gizli tutulan GPU iş atayıcısı yapmaktadır. Her SM veya CU’da kernel blokları thread grupları halinde çalıştırılmaktadır. Bu thread gruplarına Nvidia’da “warp”, AMD’de ise “wavefront” adı verilmektedir [3,4]. Aynı warp/wavefront’ta yer alan thread’ler SM ve CU’larda aynı anda paralelde çalıştırılmaktadırlar. Hem Nvidia, hem AMD iş atayıcıları SM ve CU’lara birden çok sayıda warp/wavefront ataması yapmaktadırlar. Burada her iki GPU üreticisi de ortak bir şeyi amaç edinmektedirler: veri transfer gecikmesini gizlemek! Bir grup thread veriye ulaşılmasını beklerken hazır durumdaki thread grupları SM ve CU’larda çalışabilmekte ve veriye ulaşma gecikmesinin etkisi böylelikle gizlenebilmektedir.

Şekil 2: Basit bir GPU mimarisinin bileşenleri [7].
GPU’lar genel amaçlı uygulamalar için CUDA ve OpenCL gibi API’lerle programlanabilmektedir. CUDA sadece Nvidia GPU’ları için geçerliyken OpenCL hem AMD, hem de Nvidia GPU’ları için kullanılabilmektedir.
Tipik bir GPU program akışı şu adımlardan oluşmaktadır:
- Kernel’in tanımlandığı program kaynak kodunun yüklenmesi,
- GPU’yla etkileşime girilecek bağlamın (context) yaratılması,
- Bağlam içinde kullanılacak komut kuyruğunun yaratılması,
- GPU’ya veri transferi yapabilmek için GPU belleğinde buffer’ların yaratılması,
- Hesaplama için gerekli verilerin GPU belleğindeki buffer alanlarına yazılması,
- Yaratılan bağlamda yüklenen kaynak kodundan kernel programının yaratılması,
- Kernel programının derlenmesi,
- Programdan kernel’in yaratılması,
- Kernel inputlarının yaratılmış buffer’lardan verilmesi,
- Kernel’in çalıştırılması,
- Host’a sonuçların okunması,
- Yaratılan kaynakların serbest bırakılması.
GPU’lar Hesaplamalar için Nasıl Kullanılırlar?
GPU’ların paralelleştirilebilen ve hesaplama yükünün çok olduğu işlemlerde kullanılabilmeleri için birçok yöntem bulunmaktadır.
GPU’lar CUDA ve OpenCL gibi API’ler kullanılarak programlanabilirler. CUDA (Compute Unified Device Architecture) Nvidia tarafından sağlanan ve C programlama dilini baz alan bir API’dir [1]. OpenCL (Open Computing Language) ise C’ye benzer bir dili olan standartlaşmış bir API’dir ve heterojen platformlardaki hesaplama cihazlarının programlanabilmesini sağlamaktadır [5].
GPU’lar veri üzerinde paralelde işlem yapmayı gerektiren programlar için de kullanılabilir. Tek Komut Çok Veri (Single Instruction Multiple Data – SIMD) modeli GPU’larca desteklenmektedir. Bu yapıda GPU’ya ait her SP ya da CU aynı hesaplama işini verinin bir parçası üzerinde paralelde gerçekleştirebilir. C++ gibi programlama dillerinin veriyi paralelde işleme için desteği bulunmaktadır.
GPU’lar işlerin paralelde çalıştırılması için de kullanılabilirler. Bu çalışma yapısında hesaplama işleri alt işlere ayrılırlar. Bu alt işler kendi içlerinde bağımlılıklara sahip olduklarından yönlü ve döngü içermeyen bir çizge (Directed Acyclic Graph – DAG) olarak modellenebilirler. DAG’ın parçaları paralelde SM ya da CU’lar üzerinde DAG içindeki bağımlılıklarına göre çalıştırılabilirler.
Birden çok GPU aynı host’a bağlanabilir ve host’ta çalışan uygulamalar bu GPU’ları kullanabilirler. Ancak GPU’ları kullanması için bir host’un mutlaka bir veri yoluyla GPU’ya bağlanması şart değildir. MPI gibi mesaj aktarma arayüzleri sayesinde bir host doğrudan bir veri yoluyla bağlı olmasa bile bir ağ bağlantısı sayesinde uzaktaki bir GPU’yu hesaplama için kullanabilmektedir. Böylece yüksek performanslı hizmet veren hesaplama kümelerinin oluşması mümkün olmaktadır.
GPU’lar ayrıca GPU hızlandırmasını destekleyen kütüphaneler aracılığıyla da kullanılabilmektedirler. Eğer GPU desteği aktifleştirilirse bu kütüphaneler hesaplama işlerini hızlandırmak için platformdaki GPU’lardan faydalanabilmektedirler. Örneğin ImageMagick [8] ve FFMPEG [9] kütüphanelerinin GPU desteği bulunmaktadır.
GPU ile Hesaplamanın Uygulama Alanları
GPU’lar sadece grafik hesaplama işleri ya da bilimsel hesaplama işleri için değil, endüstrinin birçok alanında da kullanılmaktadırlar. Finans, çevre, güvenlik ve koruma, akışkanlar dinamiği, elektronik tasarım otomasyonu, endüstriyel kontrol, medya ve eğlence, medikal görüntüleme, petrol ve gaz, kimyasal hesaplama ve biyoloji (biyoenformatik, mikroskopi, moleküler dinamikler, kuantum kimya), nümerik analiz, veri bilimi, bilimsel görüntüleme ve daha birçok alan GPU’lardan faydalanmaktadır [6].
Literatürdeki çalışmalar otonom araçlardaki otomotiv işlerinde GPU’ların büyük bir rol oynayacaklarını göstermektedir [2]. Bu kapsamda GPU’lar ortam algılamada, araç tespitinde, şerit tespitinde, yaya tespitinde, trafik ışığı tanımada, şöförün gözünün kapandığının tespit edilmesinde, ses tanımada ve yol planlamada kullanılmaktadırlar.
GPU’lar ayrıca sınırda hesaplama (Edge Computing) uygulamalarında da önemli bir rol oynayacaklardır. Sınırda hesaplama uzaktaki bulutta yer alan hesaplama gücünü verinin üretildiği ağların sınırlarına taşıyarak gecikmeleri azaltmayı amaçlamaktadır. Bulut ve sınırda hesaplama için Docker gibi konteyner teknolojileri son yıllarda sıkça kullanılmaktadır. GPU üreticileri de bu amaçla GPU destekleyen konteyner imajlarını sunmaktadırlar.
Medianova olarak biz sunduğumuz yüksek performanslı CDN hizmetlerimizde GPU’ları hızlı görüntü ve video işleme amaçlarıyla kullanıyoruz.
Sonuç
GPU ile hesaplama uzun yıllardır sürekli bir evrim yaşamaktadır ve şu anda birçok alanda hesaplama sistemlerinin vazgeçilmez bir parçası haline gelmiştir. Diğer teknolojilerde olduğu gibi, GPU hesaplama da ihtiyaçlar nedeniyle ortaya çıkmıştır. Bizler GPU ile hesaplamanın geleceğin akıllı uygulamalarının geliştirilmesinde büyük bir öneme sahip olacağına inanıyoruz.
Kaynaklar
- Augonnet, C. (2011). Scheduling Tasks over Multicore machines enhanced with accelerators: a Runtime System’s Perspective (Doctoral dissertation). Retrieved from https://tel.archives-ouvertes.fr/tel-00777154/document
- Xu, Y., Wang, R., Li, T., Song, M., Gao, L., Luan, Z. and Qian, D. (2016). Scheduling tasks with mixed timing constraints in GPU-powered real-time systems. Proceedings of the 2016 International Conference on Supercomputing. Istanbul, Turkey.
- Cruz, R., Drummond, L., Clua, E. and Bentes, C. (2017). Analyzing and estimating the performance of concurrent kernels execution on GPUs. WSCAD 2017 – XVIII Simposio em Sistemeas Computacionais de Alto Desempenho.
- Graphics Core Next. (n.d.). In Wikipedia. Retrieved April 22, 2019, from https://en.wikipedia.org/wiki/Graphics_Core_Next
- (n.d.). In Wikipedia. Retrieved April 24, 2019, from https://en.wikipedia.org/wiki/OpenCL
- GPU-Accelerated Applications. (2019). Retrived April 24, 2019, from https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/tesla-product-literature/gpu-applications-catalog.pdf
- Nvidia GF100. (2010).[White Paper]. Retrieved April 24, 2019, from https://www.nvidia.com/object/IO_89569.html.
- (2019). Retrieved April 24, 2019, from https://imagemagick.org/index.php.
- (2019). Retrieved April 24, 2019, from https://ffmpeg.org/.




